



Every Millisecond Counts: Latency Benchmarking of Alice Guardrails


TL;DR
In AI applications like NPCs or banking bots, even a slight delay in response time can ruin the user experience and make a brand feel untrustworthy. Many companies worry that adding safety guardrails will create "lag," but our latest performance benchmarks prove that security and speed can coexist. We tested 30,000 multilingual prompts across various safety categories, including prompt injection and PII masking, and found that the system maintained an average response time of just 68ms. With 95% of all requests finishing in under 120ms, these guardrails run invisibly in the background, keeping interactions safe without interrupting the natural rhythm of the conversation.
In AI-powered experiences, nothing breaks immersion faster than a pause that feels just a little too long. Whether you're deep inside a fantasy game negotiating with a non-player character (NPC), bantering with a virtual companion, or checking your banking app late at night about a suspicious transaction.
The magic of these interactions lies in flow. When responses feel instant and natural, the conversation feels authentic. But the moment lag creeps in, the illusion breaks. An NPC feels mechanical. A financial agent feels less trustworthy. The rhythm is lost.
That's why low latency matters. But here's the challenge: safety is just as critical. Guardrails protect users, models, and sensitive information in real time, but if they slow things down, the experience collapses. The question is: can safety and speed coexist with LLM guardrail implementation?
This blog details how we tested WonderFence under production conditions to prove that safety enforcement with real-time LLM guardrails doesn't come at the expense of responsiveness.
We frequently receive inquiries from prospective clients regarding the latency performance of our real-time Guardrails. Specifically, they want to know whether the system can meet production Service Level Objectives (SLOs), how it handles multilingual prompts, and its performance across varied prompt lengths. To provide transparency and confidence, we conducted a comprehensive latency benchmark under production conditions.
This blog is part of our ongoing effort to provide transparency into how WonderFence performs in production conditions. For a broader look at how we benchmark safety and security across categories, see our AI Security Benchmark Report.
Latency as a Security Requirement
When we talk about latency, we're not only talking about performance. In safety-critical AI applications, it's a safety and security requirement.
- Attack surface exposure: Even short delays open windows for prompt injection or malicious input to slip through.
- Real-time data protection: Personally identifiable information (PII) must be masked before it leaves the system.
- Inline enforcement: Guardrails need to act before inference completes, otherwise unsafe outputs may still reach end users.
- Operational scalability: Consistent performance under load ensures that guardrails can scale with enterprise demand without gaps in protection.
In short, low latency is the difference between safety working invisibly in the background, and safety breaking the experience.
Benchmark Methodology
We evaluated the latency of our Guardrails API using the Grafana K6 performance testing tool. The test environment replicated real-world load by targeting our production infrastructure, which handles thousands of requests per second.
The benchmark included approximately 30,000 prompts:
- Sourced from Hugging Face open-source datasets
- Augmented with internal adversarial and benign datasets
- Multilingual (20+ languages)
- Varied prompt lengths and encoding patterns
The following safety detectors were active during the test:
- Impersonation
- System Prompt Override
- Encoding (e.g. ROT13, diacritics, obfuscation)
- Personal Identifiable Information (PII)
- Bullying & Harassment
- Suicide and Self-Harm
- Adult Content
- Hate Speech
- Child Sexual Abuse Content (CSAM)
- Graphic Abusive Language
Results
The benchmark measured end-to-end latency (including network and processing overhead at our public API endpoint).
Latency Metrics:
- Average Response Time: 68.68 ms
- 90th Percentile (P90): 101.34 ms
- 95th Percentile (P95): 119.23 ms
Latency Heat map:

P(95)Latency overtime:
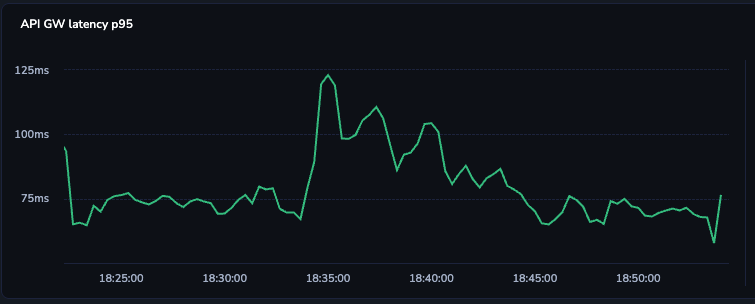
These figures validate our ability to support real-time production workloads where latency budgets are strict, including LLM agents, real-time moderation systems, and conversational UIs.
Architecture Optimized for Speed and Accuracy
Our ability to achieve sub-120ms latency isn't accidental; it's the result of architectural choices designed specifically for real-time enforcement.
Key design elements include:
- Lightweight model ensembles tuned for both throughput and precision.
- Hardware-aware routing and auto-scaling to absorb bursts of demand.
- Precompiled detection pipelines covering the full range of safety dimensions.
- Early exit conditions to accelerate benign classifications.
- Language-agnostic token normalization to handle diverse, multilingual inputs.
Together, these optimizations allow guardrails to maintain speed without compromising on detection accuracy or breadth of coverage.
Conclusion
Our benchmarks prove that WonderFence consistently meet sub-120ms latency SLOs across languages and input types, fast enough to keep pace with the most demanding real-time AI applications. But the numbers are only part of the story.
What they really mean is that the flow stays unbroken. A player can stay immersed in a fantasy world. A customer can feel reassured by their virtual banker in a stressful moment. A traveler can get instant, safe guidance from a chatbot on the way to their gate.
Low-latency guardrails make safety invisible, catching risks before they surface, without interrupting the rhythm of conversation. They are the stagehands behind the curtain, making sure every interaction feels instant, natural, and trustworthy.
Want to understand the techniques that make this possible?
Watch our on-demand webinar: Distilling LLMs for Safer, Production-Ready AI.What’s New from Alice

Curiouser Soundbites: What a Former Google Cloud CISO Wants Leaders to Know About AI
Everyone's watching the flood of new AI vulnerabilities. Former Google Cloud CISO Phil Venables is watching something else, and it's the shift leaders can't afford to miss.

The Former Google Cloud CISO's Take on AI, Agents, and What Comes Next
There's a lot of noise around AI and security right now, and not many people who can cut through it the way Phil Venables can. He was CISO at Goldman Sachs, then the first CISO for Google Cloud, and he's now a partner at Ballistic Ventures. In this episode, he tells us why attackers scaling up worries him more than the vulnerabilities themselves, what trust even means when an agent is acting in your environment, and why the answer to most of this comes back to the same fundamentals we've leaned on for years.

It Takes AI to Break AI: The Case for AI Red Teaming
As AI systems gain autonomy, organizations need security approaches built specifically for AI behavior. Learn why AI-driven red teaming is becoming a critical defense layer.

Demystifying AI Red Teaming
Your AI passed every check. That doesn't mean it's safe. Learn how to red team AI systems before adversaries find the gaps you missed.