



AI Skills Security: A Practitioner’s Guide to Emerging Threats


TL;DR
The transition to agentic AI has introduced a new attack surface where indirect prompt injection and multi-agent trust gaps lead to systemic vulnerabilities. Alice launched a new tool to scan AI agent skills for security threats.
AI Skills represent a fundamental shift in attack surface architecture
These interfaces, variously called tools, functions, plugins, or agents, transform large language models from stateless text generators into active systems that can query databases, execute code, and interact with external services.
This capability introduces LLM security risks that have no direct parallel in traditional software: prompt injection through retrieved content, confused deputy attacks via tool calls, and data exfiltration through agent-to-agent trust.
Security teams must now use AI security tools to defend against adversaries who can manipulate AI behavior through carefully crafted text embedded in documents, websites, or even seemingly innocuous data fields.
Research shows that 82.4% of state-of-the-art LLMs execute malicious commands from peer agents that they would refuse from direct user input, a systemic vulnerability in multi-agent architectures that cannot be patched through prompt engineering alone.
From ChatGPT plugins to MCP: the evolution of AI Skills
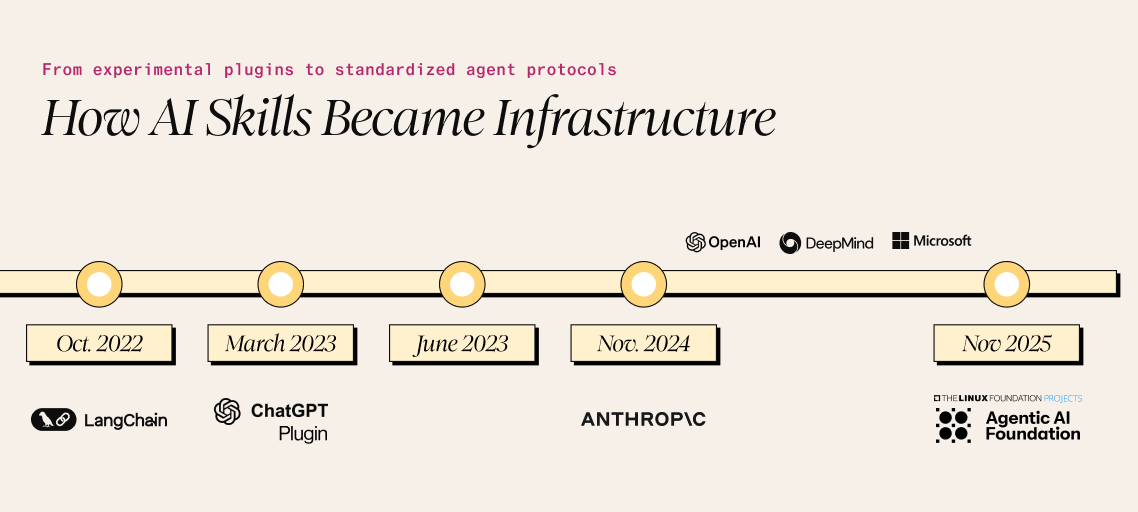
The modern AI Skills ecosystem emerged rapidly between 2022 and 2025.
LangChain launched in October 2022, introducing the concept of “tools” and “agents” for LLM orchestration just weeks before ChatGPT’s public debut. OpenAI followed with ChatGPT plugins on March 23, 2023, enabling third-party integrations described by manifest files and OpenAPI specifications.
The crucial technical innovation came on June 13, 2023, when OpenAI released function-calling models, fine-tuned to detect when external functions should be invoked and respond with structured JSON rather than prose.
Anthropic’s Model Context Protocol (MCP), open-sourced in November 2024, represents the current state of the art. MCP defines three primitives: Tools (model-controlled), Resources (application-controlled), and Prompts (user-controlled), with transport-agnostic communication via stdio or HTTP. The protocol has achieved remarkable adoption: Over 97 million monthly SDK downloads and major integration by OpenAI, Google DeepMind, and Microsoft.
In November 2025, MCP was donated to the Linux Foundation’s Agentic AI Foundation, signaling its emergence as an industry standard.
AI Skills → Someone else’s instructions
AI skills were meant to enable your AI assistants or agents to perform tasks consistently in some way of a template. These SKILLS.md files can be found online or are hosted at links that you can provide to your agents and, seamlessly, your agent now knows kung-fu (Matrix Reference). When you go one level deeper, all of these instructions are coming from unverified, community sources. So those skills your AI is learning are really just someone else’s instructions.
This introduces prompt injection as an attack vector with no analogue in traditional software: malicious instructions embedded in retrieved data can override system prompts and hijack application behavior.
Unfortunately, the AI space isn’t really prepared for supply chain issues at this scale, and we have the receipts.
A 2024 analysis of 1,038 ChatGPT plugins found systemic security failures: 173 plugins (17%) had broken access control vulnerabilities, and 368 plugins (35%) leaked developer credentials, including API keys and OAuth tokens. The ChatGPT plugin ecosystem lacks code signing, standardized SBOMs, or version pinning, security controls considered baseline for package managers like npm or PyPI.
Unlike npm’s trusted publishing or PyPI’s verified publishers, AI skill registries provide minimal provenance verification. Anthropic’s own Claude Code security documentation explicitly states that “Anthropic does not manage or audit any MCP servers” - the security model depends entirely on enterprise allowlisting and developer diligence.
The October 2025 Smithery MCP hosting breach demonstrated the consequences: a path traversal vulnerability exposed the platform’s Fly.io API token, compromising 3,000+ deployed applications and customer API keys.
Documented exploits reveal systematic vulnerabilities
Real-world attacks against AI Skills systems have moved from theoretical to actively exploited. The vulnerabilities span the entire stack, from serialization layers to inter-agent communication to browser-based exfiltration.
LangChain critical vulnerabilities
LangChain has been at the center of several high-severity security disclosures, illustrating how AI orchestration frameworks can turn model output into an execution-grade attack surface.
CVE-2025-68664 (LangGrinch), disclosed in December 2025, affectslangchain-core versions prior to 0.3.81 and 1.0.0–1.2.5, and carries a CVSS score of 9.3. The vulnerability stems from improper escaping in the dumps() and dumpd() serialization functions.
Specifically, these functions fail to sanitize user-controlled dictionaries that include the reserved "lc" key. This allows attackers to inject malicious instructions via LLM response fields such as additional_kwargs. When the serialized output is later processed, those instructions can execute inside trusted namespaces.
Successful exploitation enables secret extraction from environment variables and arbitrary class instantiation, effectively resulting in remote code execution via Jinja2 template injection. Crucially, this attack can be triggered through prompt injection: an adversary crafts inputs that cause the LLM itself to emit specially structured metadata, which then executes during serialization, without any explicit code exploit.
MCP ecosystem breach timeline
The Model Context Protocol’s rapid adoption has been accompanied by an equally rapid discovery of vulnerabilities:
- April 2025: The WhatsApp MCP server was exploited through tool poisoning; a legitimate “random fact” tool was transformed into a sleeper backdoor that exfiltrated entire chat histories.
- June 2025: CVE-2025-49596 exposed unauthenticated RCE in Anthropic’s MCP Inspector. Victims merely inspecting a malicious MCP server could have their filesystems accessed and API keys stolen.
- July 2025: CVE-2025-6514 affected mcp-remote (437,000+ downloads) via OS command injection through malicious authorization endpoints, a supply chain vulnerability affecting Cloudflare, Hugging Face, and Auth0 integrations.
- August 2025: CVE-2025-53109 and CVE-2025-53110 demonstrated sandbox escapes in Anthropic’s filesystem MCP server, enabling arbitrary file access on host systems.
Attack surfaces in skill-enabled architectures
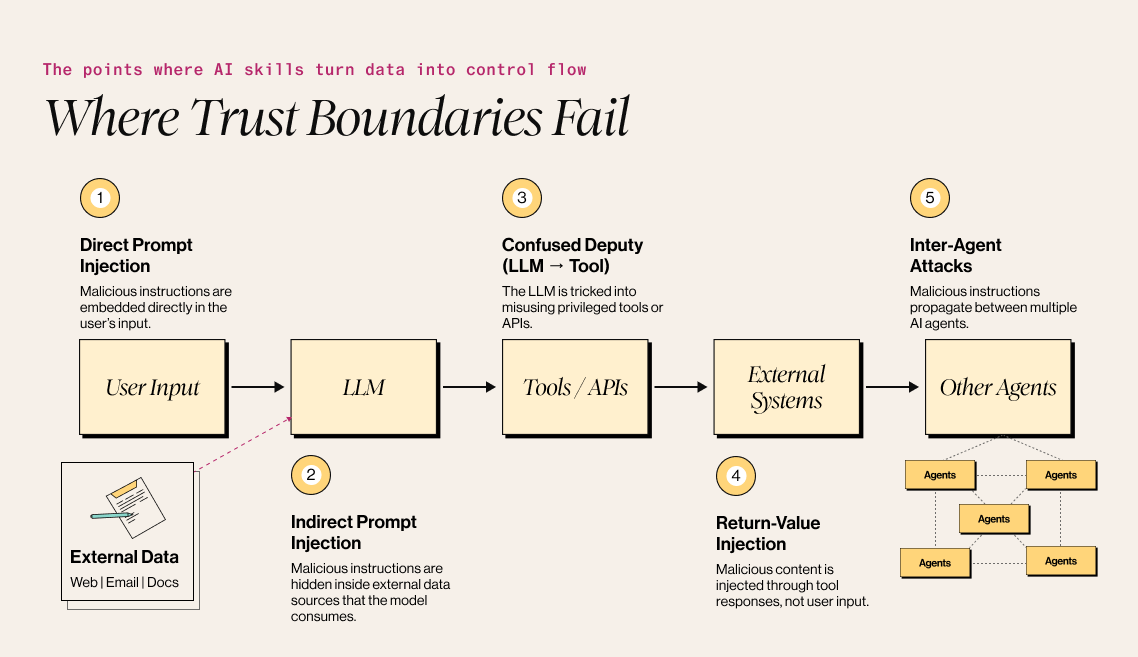
Understanding LLM attack vectors and where vulnerabilities emerge requires mapping the data flows in typical AI skills architectures. Security researchers generally identify five primary attack surfaces, each reflecting a different point where trust boundaries break down.
- User input to the LLM (direct prompt injection) remains the most visible attack vector. In these cases, attackers embed malicious instructions directly into prompts in an attempt to override system instructions. However, success rates for direct prompt injection have declined in hardened systems, as models are increasingly trained to resist explicit jailbreak attempts.
- External data to the LLM (indirect prompt injection) represents a far more dangerous vector. When an agent retrieves web pages, reads emails, or queries databases, any malicious content within that data enters the model’s context with the same priority as system instructions. A 2023 research demonstrated that retrieved prompts can function as a form of “arbitrary code execution,” because LLMs cannot reliably distinguish instructions from data.
- The LLM-to-tool interface (confused deputy attacks) exploits the privileged access that agents have to external tools. In these scenarios, the LLM becomes an unwitting intermediary, executing attacker-controlled instructions through trusted tools.
- Tool responses back to the LLM (return-value injection) complete the attack loop. Malicious content returned by tools (whether from compromised APIs, poisoned databases, or adversarial websites) can influence subsequent model behavior.
- Inter-agent communication (multi-agent attacks) presents the most severe systemic risk. As noted earlier, research published in July 2025 evaluating 17 state-of-the-art LLMs found that 82.4 % executed malicious commands from peer agents that they would refuse if issued directly by a user, underscoring how trust assumptions between agents fundamentally alter model behavior. The implicit trust between agents in orchestrated systems enables lateral movement: compromise a single agent, and an attacker can effectively gain access to the entire agent mesh.
Threat modeling AI agents using the lethal trifecta
Simon Willison’s “lethal trifecta” concept provides the clearest framework for understanding when AI Skills systems become dangerous. Catastrophic data exfiltration becomes possible when three conditions combine:
- Access to sensitive data: credentials, PII, private documents
- Exposure to untrusted content: web pages, emails, public repositories
- Ability to externally communicate: web requests, file sharing, email
Meta formalized this as the Agents Rule of Two: agents should satisfy no more than two of these three properties (with “change state” substituting for external communication). If all three are required, the system must include human-in-the-loop supervision.
For example, a coding agent with repository access (sensitive data), that is able to read GitHub issues (untrusted content), and can post comments (external communication) satisfies all three conditions. The May 2025 GitHub MCP breach demonstrated exactly this scenario: prompt injection in a public issue hijacked an agent into exfiltrating private repository contents, internal project details, and salary information to a public PR.
Trust boundary violations in typical deployments
By default, LLMs cannot be trusted to enforce trust boundaries. They process instructions and data identically, meaning security must be implemented in deterministic code surrounding the LLM.
Applying Mitigation strategies to AI Skills that actually work
While AI Agents with skills may have fundamentally different ways of interacting with their environment in a novel way, we can apply proven LLM security testing strategies to this new problem.

- Sandboxing provides the strongest isolation for code execution. The spectrum ranges from Docker containers (process-level isolation, suitable for trusted internal code) to gVisor (user-space kernel, multi-tenant SaaS) to Firecracker microVMs (full hypervisor isolation, maximum security for public code execution).
- Claude Code’s implementation demonstrates the pattern via containerized execution with filesystem writes restricted to project directories and network access limited to approved domain allowlists.
- Guardrails at input and output provide defense in depth.
- Input guardrails include:
- prompt injection detection (using vector databases, YARA rules, or transformer classifiers),
- topic relevancy checks, and identity binding.
- Output guardrails validate responses against:
- Schemas
- Resource level permissions access
- System prompt leak detections
- Input guardrails include:
- Capability restriction implements least privilege:
- Whitelist only necessary APIs for each agent.
- Use read-only tokens where writes aren’t needed.
- Store credentials in vaults, never files.
- OWASP guidance emphasizes: “The whitelisting of rules is very crucial, otherwise the model can go rogue and call any API.”
- Human-in-the-loop controls remain essential for high-risk operations. Implement approval points for production database writes, financial transactions, and actions outside defined boundaries. The task-splitting strategy proposed by Martin Fowler creates natural checkpoints: LLM creates research plan → human reviews → LLM executes research → human reviews → LLM applies changes.
- Monitoring and observability enable detection and forensics. Log all agent operations and tool invocations with parameters. Use eBPF for kernel-level observation of AI workflows. Detect anomalous tool use patterns, unusual data access, and token consumption spikes.
Making AI Skills Risk Visible in Practice
Many failures in what should be secure AI systems stem from a lack of visibility into what AI skills actually do once installed. Permissions, agent-to-agent behavior, and execution paths are often implicit, leaving teams to infer risk after deployment rather than assess it upfront.
To make these risks more explicit in practice, we built Caterpillar, a lightweight tool that scans AI skills before or after installation and surfaces security-relevant behavior, such as over-permissive capabilities or uncontrolled agent coordination, along with contextual explanations of why those patterns matter. Before adding a skill from a source you’re unsure about, try asking Caterpillar what it sees:

Alice is making it available to practitioners to evaluate how well this approach holds up in real-world workflows and to help identify remaining blind spots. Try it out - https://caterpillar.alice.io/
We also scanned the top 50 skills on “Skills.sh”, a popular marketplace for finding and downloading new skills. You can see what we’ve found so far here: https://caterpillar.alice.io/report
See which popular skills have the most risk
Learn MoreWhat’s New from Alice


Afraid AI Will Replace You? Here's the One Skill It Can't
James Villarrubia went from building AI for NASA's drone and aerospace programs to becoming CTO of a travel tech company. In this episode, he and Mo get into why curiosity might be the most important skill in the AI era, what happens to our brains when we stop pushing back on the answers we get, and why the people most resistant to AI might actually be seeing something the rest of us are missing.

It Takes AI to Break AI: The Case for AI Red Teaming
As AI systems gain autonomy, organizations need security approaches built specifically for AI behavior. Learn why AI-driven red teaming is becoming a critical defense layer.

Evaluation of Instagram Teen Accounts
This report evaluates default and opt-in content protections under real-world and adversarial conditions. The study examines safeguard effectiveness, resilience against attempts to surface inappropriate content, and platform improvements made following testing.